Nian (Oakley) Liu
Master of Computer Science
Beijing University of Posts and Telecommunications
Home
CV
Publications
Personal
SocialContact:
Department of Computer Science
Beijing University of Posts and Telecommunications
Xitucheng Road 10
Beijing haidian district, China
Post: 100876
Phone: +86 13041092011
Published Papers
Revisiting Graph Contrastive Learning from the Perspective of Graph Spectrum
Authors: Nian Liu, Xiao Wang, Deyu Bo, Chuan Shi, Jian Pei
Conference: Advances in neural information processing systems (NeurIPS), 2022
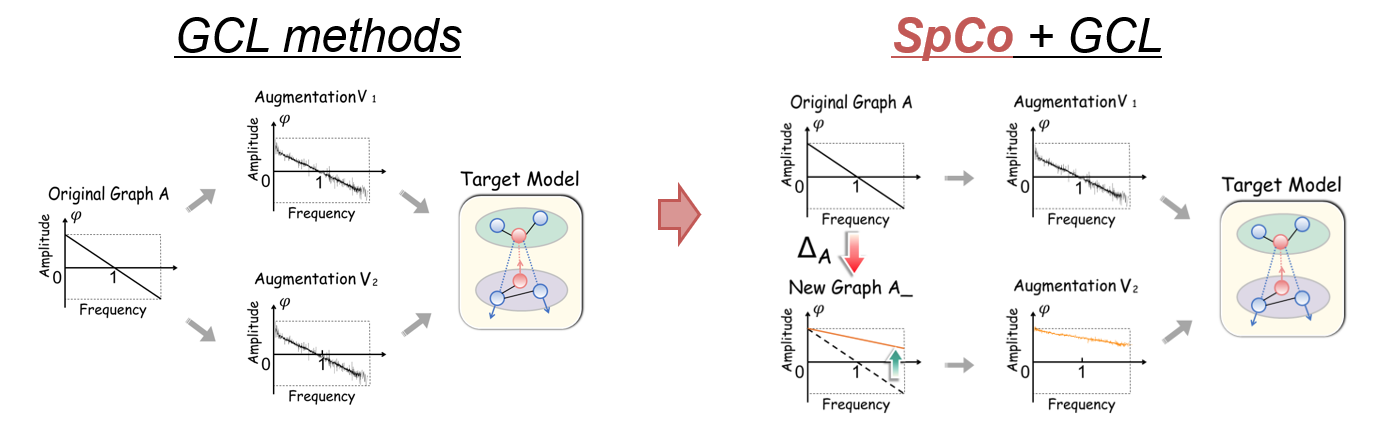
Overview: This is the first attempt to fundamentally explore the augmentation strategies for GCL from spectral domain. We not only reveal the general graph augmentation rule behind different augmentation, but also explain why GCL works by proposing the contrastive invariance theorem. Our work provides deeper understanding on the nature of GCL.
Code: https://github.com/liun-online/SpCo
Graph Contrastive Learning (GCL), learning the node representations by augmenting graphs, has attracted considerable attentions. Despite the proliferation of various graph augmentation strategies, some fundamental questions still remain unclear: what information is essentially encoded into the learned representations by GCL? Are there some general graph augmentation rules behind different augmentations? If so, what are they and what insights can they bring? In this paper, we answer these questions by establishing the connection between GCL and graph spectrum. By an experimental investigation in spectral domain, we firstly find the General grAph augMEntation (GAME) rule for GCL, i.e., the difference of the high-frequency parts between two augmented graphs should be larger than that of low-frequency parts. This rule reveals the fundamental principle to revisit the current graph augmentations and design new effective graph augmentations. Then we theoretically prove that GCL is able to learn the invariance information by contrastive invariance theorem, together with our GAME rule, for the first time, we uncover that the learned representations by GCL essentially encode the low-frequency information, which explains why GCL works. Guided by this rule, we propose a spectral graph contrastive learning module (SpCo1 ), which is a general and GCL-friendly plug-in. We combine it with different existing GCL models, and extensive experiments well demonstrate that it can further improve the performances of a wide variety of different GCL methods.
Update soon
Update soon
Compact Graph Structure Learning via Mutual Information Compression
Authors: Nian Liu, Xiao Wang, Lingfei Wu, Yu Chen, Xiaojie Guo, Chuan Shi
Conference: International World Wide Web Conference (TheWebConf), 2022
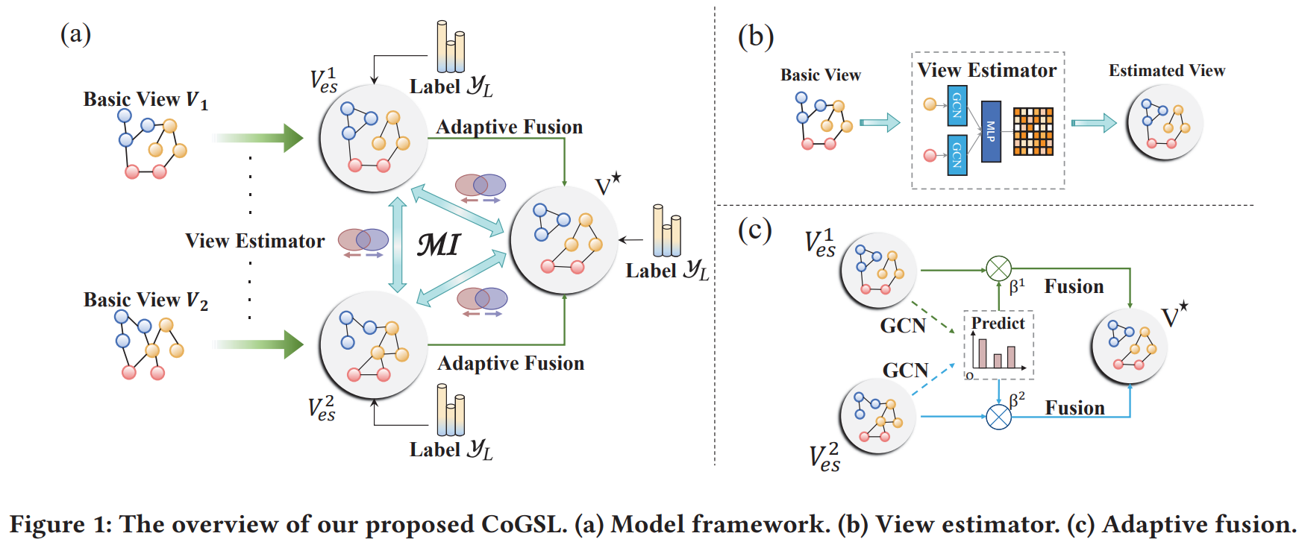
Overview: In this paper, we are the first to define the “optimal graph structure” in principle by Information theory, which can achieve effectiveness and robustness simultaneously.
Code: https://github.com/liun-online/CoGSL
Graph Structure Learning (GSL) recently has attracted considerable attentions in its capacity of optimizing graph structure as well as learning suitable parameters of Graph Neural Networks (GNNs) simultaneously. Current GSL methods mainly learn an optimal graph structure (final view) from single or multiple information sources (basic views), however the theoretical guidance on what is the optimal graph structure is still unexplored. In essence, an optimal graph structure should only contain the information about tasks while compress redundant noise as much as possible, which is defined as "minimal sufficient structure", so as to maintain the accurancy and robustness. How to obtain such structure in a principled way? In this paper, we theoretically prove that if we optimize basic views and final view based on mutual information, and keep their performance on labels simultaneously, the final view will be a minimal sufficient structure. With this guidance, we propose a Compact GSL architecture by MI compression, named CoGSL. Specifically, two basic views are extracted from original graph as two inputs of the model, which are refinedly reestimated by a view estimator. Then, we propose an adaptive technique to fuse estimated views into the final view. Furthermore, we maintain the performance of estimated views and the final view and reduce the mutual information of every two views. To comprehensively evaluate the performance of CoGSL, we conduct extensive experiments on several datasets under clean and attacked conditions, which demonstrate the effectiveness and robustness of CoGSL.
Self-supervised Heterogeneous Graph Neural Network with Co-contrastive Learning
Authors: Xiao Wang, Nian Liu, Hui Han, Chuan Shi
Conference: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (KDD), 2021
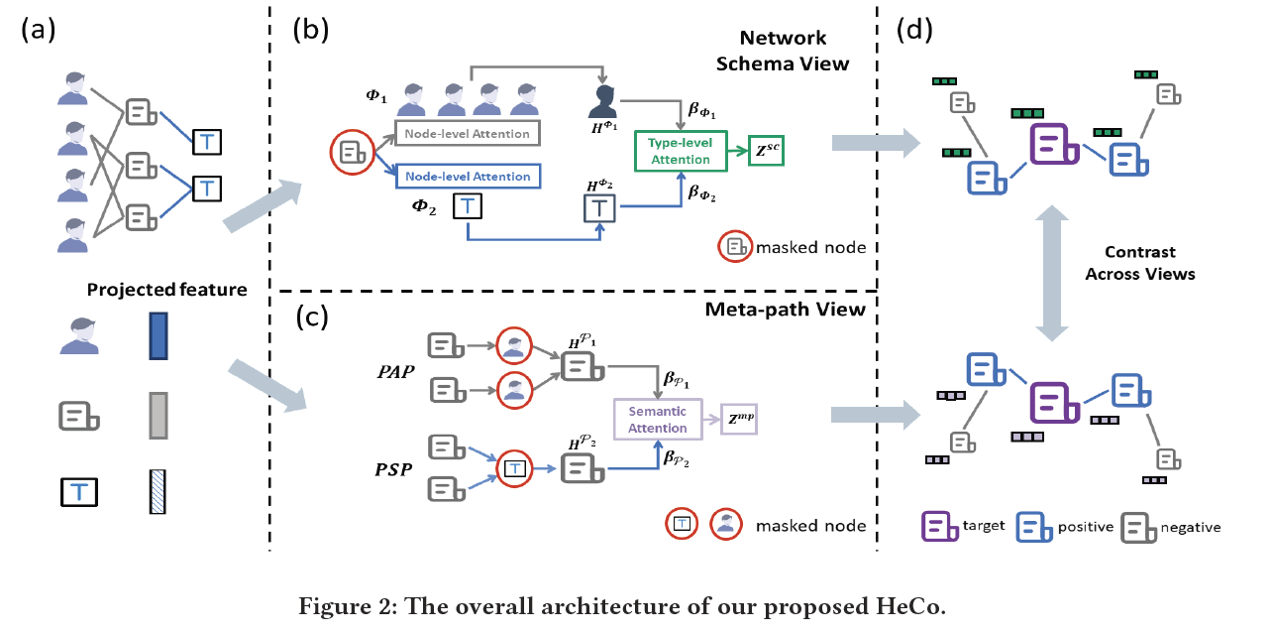
Overview: HeCo is the first to conduct cross-view contrastive learning in heterogeneous graph. According to PaperDigest, this paper is one of the most influential paper in KDD 2021 as for 2022/05.
Code: https://github.com/liun-online/HeCo
Heterogeneous graph neural networks (HGNNs) as an emerging technique have shown superior capacity of dealing with heterogeneous information network (HIN). However, most HGNNs follow a semi-supervised learning manner, which notably limits their wide use in reality since labels are usually scarce in real applications. Recently, contrastive learning, a self-supervised method, becomes one of the most exciting learning paradigms and shows great potential when there are no labels. In this paper, we study the problem of self-supervised HGNNs and propose a novel co-contrastive learning mechanism for HGNNs, named HeCo. Different from traditional contrastive learning which only focuses on contrasting positive and negative samples, HeCo employs cross-viewcontrastive mechanism. Specifically, two views of a HIN (network schema and meta-path views) are proposed to learn node embeddings, so as to capture both of local and high-order structures simultaneously. Then the cross-view contrastive learning, as well as a view mask mechanism, is proposed, which is able to extract the positive and negative embeddings from two views. This enables the two views to collaboratively supervise each other and finally learn high-level node embeddings. Moreover, two extensions of HeCo are designed to generate harder negative samples with high quality, which further boosts the performance of HeCo. Extensive experiments conducted on a variety of real-world networks show the superior performance of the proposed methods over the state-of-the-arts.
Embedding Heterogeneous Information Network in Hyperbolic Spaces
Authors: Yiding Zhang, Xiao Wang, Nian Liu, Chuan Shi
Journal: ACM Transactions on Knowledge Discovery from Data (ACM TKDD), 2021
Overview: We are the first to explore HIN embedding in hyperbolic spaces, naturally capture the hierarchical and power-law structure in complex network.
Heterogeneous information network (HIN) embedding, aiming to project HIN into a low-dimensional space, has attracted considerable research attention. Most of the existing HIN embedding methods focus on preserving the inherent network structure and semantic correlations in Euclidean spaces. However, one fundamental problem is whether the Euclidean spaces are the intrinsic spaces of HIN? Recent researches find the complex network with hyperbolic geometry can naturally reflect some properties, e.g., hierarchical and power-law structure. In this article, we make an effort toward embedding HIN in hyperbolic spaces. We analyze the structures of three HINs and discover some properties, e.g., the power-law distribution, also exist in HINs. Therefore, we propose a novel HIN embedding model HHNE. Specifically, to capture the structure and semantic relations between nodes, HHNE employs the meta-path guided random walk to sample the sequences for each node. Then HHNE exploits the hyperbolic distance as the proximity measurement. We also derive an effective optimization strategy to update the hyperbolic embeddings iteratively. Since HHNE optimizes different relations in a single space, we further propose the extended model HHNE++. HHNE++ models different relations in different spaces, which enables it to learn complex interactions in HINs. The optimization strategy of HHNE++ is also derived to update the parameters of HHNE++ in a principle manner. The experimental results demonstrate the effectiveness of our proposed models.
Lorentzian Graph Convolutional Networks
Authors: Yiding Zhang, Xiao Wang, Chuan Shi, Nian Liu, Guojie Song
Conference: International World Wide Web Conference (TheWebConf), 2021
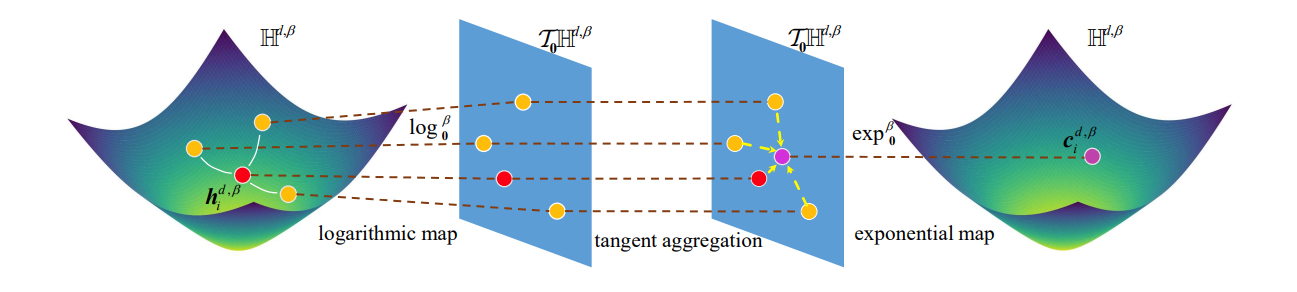
Overview: We study on the hyperbolic GCN, rebuild graph operations with Lorentzian version and design a neighborhood aggregation method based on the centroid of Lorentzian distance.
Code: https://github.com/BUPT-GAMMA/lgcn_torch
Graph convolutional networks (GCNs) have received considerable research attention recently. Most GCNs learn the node representations in Euclidean geometry, but that could have a high distortion in the case of embedding graphs with scale-free or hierarchical structure. Recently, some GCNs are proposed to deal with this problem in non-Euclidean geometry, e.g., hyperbolic geometry. Although hyperbolic GCNs achieve promising performance, existing hyperbolic graph operations actually cannot rigorously follow the hyperbolic geometry, which may limit the ability of hyperbolic geometry and thus hurt the performance of hyperbolic GCNs. In this paper, we propose a novel hyperbolic GCN named Lorentzian graph convolutional network (LGCN), which rigorously guarantees the learned node features follow the hyperbolic geometry. Specifically, we rebuild the graph operations of hyperbolic GCNs with Lorentzian version, e.g., the feature transformation and non-linear activation. Also, an elegant neighborhood aggregation method is designed based on the centroid of Lorentzian distance. Moreover, we prove some proposed graph operations are equivalent in different types of hyperbolic geometry, which fundamentally indicates their correctness. Experiments on six datasets show that LGCN performs better than the state-of-the-art methods. LGCN has lower distortion to learn the representation of tree-likeness graphs compared with existing hyperbolic GCNs. We also find that the performance of some hyperbolic GCNs can be improved by simply replacing the graph operations with those we defined in this paper.
Debiased Graph Neural Networks with Agnostic Label Selection Bias
Authors: Shaohua Fan, Xiao Wang, Chuan Shi, Kun Kuang, Nian Liu, Bai Wang
Journal: IEEE Transactions on Neural Networks and Learning Systems (IEEE TNNLS), 2022
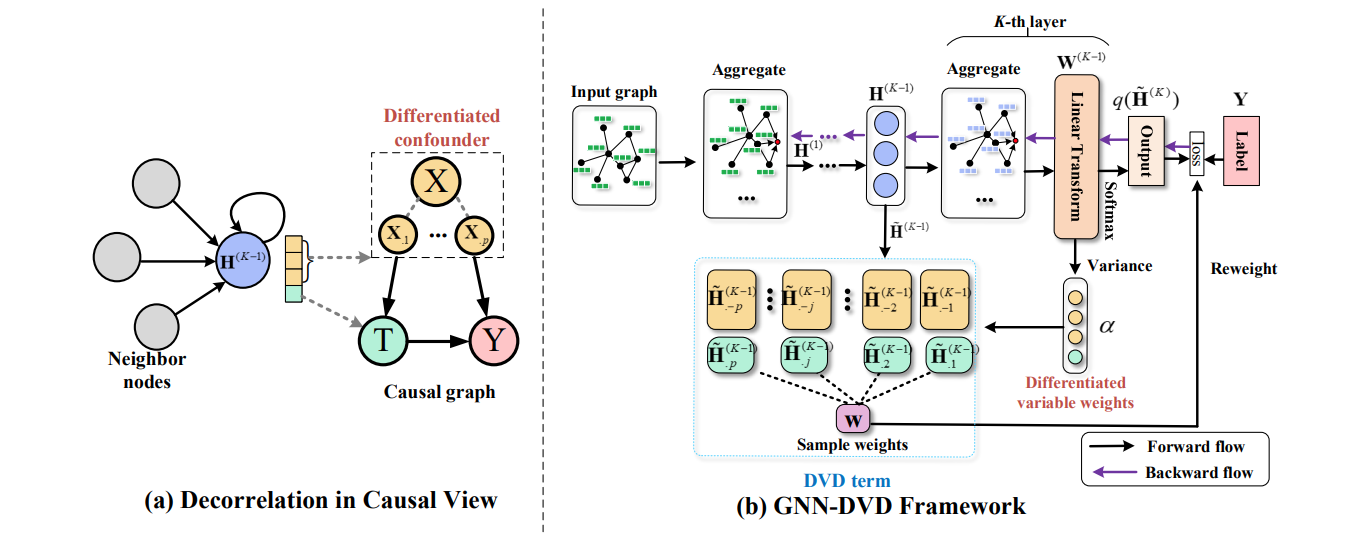
Overview: We focus on the label selection bias in GNN, and propose Debiased GNN to eliminate spurious correlation by reweighting samples and improve stability of prediction.
Code: https://github.com/googlebaba/TNNLS2022-DGNN
Most existing Graph Neural Networks (GNNs) are proposed without considering the selection bias in data, i.e., the inconsistent distribution between the training set with test set. In reality, the test data is not even available during the training process, making selection bias agnostic. Training GNNs with biased selected nodes leads to significant parameter estimation bias and greatly impacts the generalization ability on test nodes. In this paper, we first present an experimental investigation, which clearly shows that the selection bias drastically hinders the generalization ability of GNNs, and theoretically prove that the selection bias will cause the biased estimation on GNN parameters. Then to remove the bias in GNN estimation, we propose a novel Debiased Graph Neural Networks (DGNN) with a differentiated decorrelation regularizer. The differentiated decorrelation regularizer estimates a sample weight for each labeled node such that the spurious correlation of learned embeddings could be eliminated. We analyze the regularizer in causal view and it motivates us to differentiate the weights of the variables based on their contribution on the confounding bias. Then, these sample weights are used for reweighting GNNs to eliminate the estimation bias, thus help to improve the stability of prediction on unknown test nodes. Comprehensive experiments are conducted on several challenging graph datasets with two kinds of label selection biases. The results well verify that our proposed model outperforms the state-of-the-art methods and DGNN is a flexible framework to enhance existing GNNs.
Papers under Revision
Hierarchical Contrastive Learning Enhanced Heterogeneous Graph Neural Network
Authors: Nian Liu, Xiao Wang, Hui Han, Chuan Shi
Journal: IEEE Transactions on Knowledge and Data Engineering (TKDE)
Overview: This work argues that besides cross-view contrast to capture commonality in HeCo, view-specific information also should be explored by intra-view contrast.
Heterogeneous graph neural networks (HGNNs) as an emerging technique have shown superior capacity of dealing with heterogeneous information network (HIN). However, most HGNNs follow a semi-supervised learning manner, which notably limits their wide use in reality since labels are usually scarce in real applications. Recently, contrastive learning, a self-supervised method, becomes one of the most exciting learning paradigms and shows great potential when there are no labels. In this paper, we study the problem of self-supervised HGNNs and propose a novel co-contrastive learning mechanism for HGNNs, named HeCo. Different from traditional contrastive learning which only focuses on contrasting positive and negative samples, HeCo employs cross-view contrastive mechanism. Specifically, two views of a HIN (network schema and meta-path views) are proposed to learn node embeddings, so as to capture both of local and high-order structures simultaneously. Then the cross-view contrastive learning, as well as a view mask mechanism, is proposed, which is able to extract the positive and negative embeddings from two views. This enables the two views to collaboratively supervise each other and finally learn high-level node embeddings. Moreover, to further boost the performance of HeCo, two additional methods are designed to generate harder negative samples with high quality. The essence of HeCo is to make positive samples from different views close to each other by cross-view contrast, and learn the factors invariant to two proposed views. However, besides the invariant factors, view-specific factors complementally provide the diverse structure information between different nodes, which also should be contained into the final embeddings. Therefore, we need to further explore each view independently and propose a modified model, called HeCo++. Specifically, HeCo++ conducts hierarchical contrastive learning, including cross-view and intra-view contrasts, which aims to enhance the mining of respective structures. Extensive experiments conducted on a variety of real-world networks show the superior performance of the proposed methods over the state-of-the-arts.